Comments
No comments yet. You can be the first!
Most popular documents in this category





Content extract
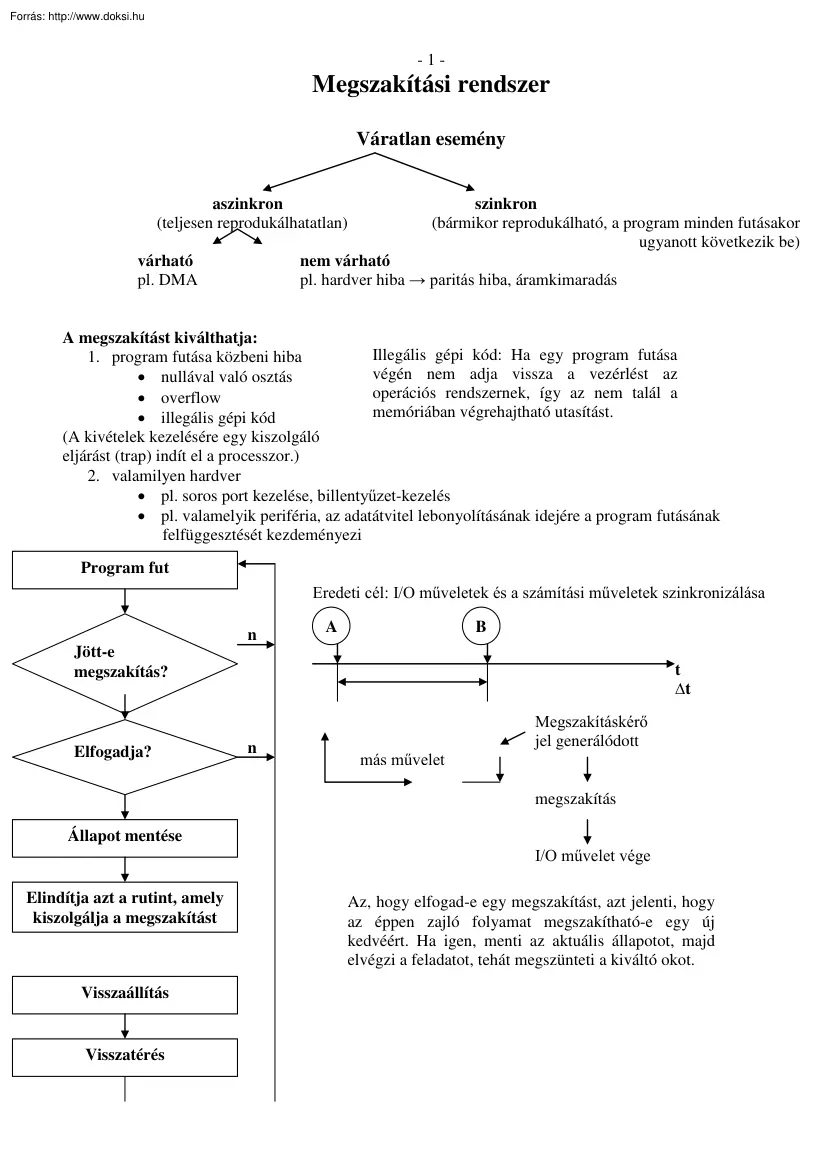
-1- Megszakítási rendszer Váratlan esemény aszinkron (teljesen reprodukálhatatlan) várható pl. DMA szinkron (bármikor reprodukálható, a program minden futásakor ugyanott következik be) nem várható pl. hardver hiba paritás hiba, áramkimaradás A megszakítást kiválthatja: Illegális gépi kód: Ha egy program futása 1. program futása közbeni hiba végén nem adja vissza a vezérlést az • nullával való osztás operációs rendszernek, így az nem talál a • overflow memóriában végrehajtható utasítást. • illegális gépi kód (A kivételek kezelésére egy kiszolgáló eljárást (trap) indít el a processzor.) 2. valamilyen hardver • pl. soros port kezelése, billentyűzet-kezelés • pl. valamelyik periféria, az adatátvitel lebonyolításának idejére a program futásának felfüggesztését kezdeményezi Program fut Megszakítási okok: Eredeti cél: I/O műveletek és a számítási műveletek szinkronizálása n A B Jött-e
megszakítás? Elfogadja? t ∆t n más művelet Megszakításkérő jel generálódott megszakítás Állapot mentése Elindítja azt a rutint, amely kiszolgálja a megszakítást Visszaállítás Visszatérés I/O művelet vége Az, hogy elfogad-e egy megszakítást, azt jelenti, hogy az éppen zajló folyamat megszakítható-e egy új kedvéért. Ha igen, menti az aktuális állapotot, majd elvégzi a feladatot, tehát megszünteti a kiváltó okot. -2A megszakítások forrásai 1. Géphibák: • az egyes eszközök valamilyen hibajavító kód segítségével ismerik fel a hibákat o A CPU regiszterei o Operatív tár o Adatátvitel • Energiaellátás hibái • Klimatizáció 2. I/O források: a perifériák megszakítás-kérő jelzései (CPU dobozon belül) 3. Külső források másik számítógép 4. Programozói források Utasítások végrehajtásakor keletkező INT-ek: • Hiba (arch. specifikusak) o Memóriavédelem megsértése o Tárkapacitás
túlcímzés (tényleges) o Címzési előírások megsértése o Aritmetikai és logikai műveletek miatti megszakítás (kivételek:tömbindex-túlcímzés, 0-val való osztás, overflow) • Szándékos o Rendszerhívások (pl. az Intel CPU-k overflow flag-je jelzi, ha túlcsordulás lépett fel Az INTO utasítással egy megszakítás kérhető: korrekció.) Megszakítások csoportosítása • Szinkron/aszinkron • Utasítások végrehajtása között (az előző utasítás eredményeképpen) vagy közben (külső) történő megszakítások Ellenélda: REP mov SB DS:SI ES DI SI++ DI++ Flag: Overflow 1 0 1 0 0 1 1 0 CX 0 1 0 • Felhasználó által explicit módon kért ill. nem kért megszakítások o Kért (az OPrendszer szolgáltatásai): Pl. INTO vagy INT3 (a programban való töréspont elhelyezésére használható, a hibakeresés érdekében (debug)) o Nem Kért: magától a gép • Felhasználó által maszkolható (letiltható) vagy nem maszkolható
megszakítások Megszakítás-kiszolgálás 1. egy egység aktiválja az INTR bemenetet 2. a CPU elfogadja ezt az INT kérést, ha megszakítható állapotban van megfelelő a prioritás nagysága a beérkezett megszakítás nincs maszkolva A 3 felt. teljesülése esetén INT elfogadva UT1 UT2 . a megszakítás vizsgálása (két ut. között nem fogadóképes) Megszakítási flagregiszter: a még nem teljesített INT kérések vannak benne 3. CPU elmenti a verembe az aktuális állapot információkat (PC, flag) -34. a megszakított program adatterének mentése (regiszterkészlet) 5. a megszakítást igénylő azonosítása (ha egy INT-hez több egység is tartozik) 6. megszakítás kiszolgálása 7. az adattér visszaállítása 8. A CPU a kiszolgálás végeztével visszaküld egy nyugtát az egységnek, az pedig deaktiválja a jelet A megszakítás kiszolgálása után a megszakított program folytatódik, vagy nem (reset). Mindegyik INT-hez tarozik egy bit:
a CPU ezeket vizsgálja, amikor fogadóképes. A megszakítást kérő azonosítása A legegyszerűbb lehetőség a megszakítások egyenkénti kiszolgálása, azok beérkezési sorrendjében. Hátránya, hogy a megszakítások kiszolgálása közben érkező megszakítást nem tudja kiszolgálni, így a halaszthatatlan kérelmek elveszhetnek. 1. Lekérdezéses (polling): Valamilyen sorrendben lekérdezzük az egységeket • Hardveres úton: daisy chain • Szoftveres úton: az operációs rendszer 2. Vektoros: A megszakítást kérő eszköz a kiszolgáló rutin kezdőcímét határozza meg a megszakítási vezérlő és a processzor számára. Több megszakítási vonal esetén minden eszköz saját megszakítást kérő vezetékkel rendelkezik, így a kérelem helye egyértelműen megállapítható. Megszakítások maszkolása • NMI: Non Maskable Interrupt (nem maszkolható megszakítás) • INTR: maszkolható megszakítás Egyes eszközök esetén a megszakítás lehetősége
engedélyezhető vagy tiltható. Ez a maszkolás, ami egy regiszter bitjeinek a beállításával történik. Így az NMI kérelmek kiszolgálása nem tiltható le, azok mindig érvényre jutnak. Parancs az elemzésre Aktuális prioritás Kiválasztó logika Elfogadta a prioritást Elfogadott prioritás maszk regiszter A megszakítási kérelmek kiszolgálási sorrendjének megállapítása történhet megszakítási vezérlővel (centralizált) és decentralizált módon (daisy chain). A memóriavédelem megsértése: Ha az operatív memóriában egy időben több, egymástól független feladat programja tárolódik, szükség van azok védelmének megszervezésére, elsősorban véletlen felülírás ellen. Ha egy program futása során "idegen" címre hivatkozik, az alkalmazott hardveres memória-védelem működésbe lép Pl. ha több program egyszerre akar elérni egy memóriaterületet (Win9x) A címzési mód megsértése: A bájt-szervezésű gépeknél az
utasítások hossza általában 2, 4 vagy 6 bájt lehet. Ez szokásosan együtt jár azzal a címzési előírással, hogy utasítás csak páros című bájttal kezdődhet. Ha például egy ugró utasítás páratlan címre ugrana, ez programhibát jelent és ezért végrehajtás helyett megszakítás történik. Hasonló címzési előírás lehet, például hogy dupla szó csak 8-cal osztható című bájttal kezdődhet. -4Prioritások kezelése Több megszakítás érkezett. Melyik a fontosabb? • Prioritás nélküli: pl. érkezési sorrend alapján időérzékeny megszakítások nem megfelelő kezelése (pl. a soros portra érkező adatot azonnal fogadni kell, különben adatvesztés) • Prioritásos Prioritási csoport: 1. védelmi rendszer megsértése és hardver hibák 2. kritikus időzítések (pl adatátvitel) 3. teljesítményt kell figyelembe venni magasabb prioritású felhasználó nagy terheltségű program Prioritás eldöntésének algoritmusa
(programozhatók általában) • Fix prioritás: az egységekhez van hozzárendelve, nem módosítható • Körbeforgó prioritás – több eszköz rendelkezik azonos prioritással először a C hajtódik végre, utána az ilyen típusúnak lesz a legkisebb a prioritása (de csak az azonos prioritásúak között) A B C Azonos prioritás • Speciális maszk (letilthatók a bizonyos egységektől érkező kérések) A prioritásos megszakítás-kezeléshez hasonló módszerek • Hardver lekérdezéses (daisy chain) databus * INTACK CPU 1 1 U1 0 0 1 1 U1 1 0 1 0 U1 0 1 0 0 U1 0 1.U3 0 2.U2 INTR • • Szoftver lekérdezéses: A programban beállított vizsgálati sorrend határozza meg a prioritást. Prioritási csoportok szervezése -5- • Párhuzamos kiszolgálású megszakítási rendszer Megszakítási rendszerek szintek szerint • Egyszintű: Nincs lehetőség a kiszolgáló rutin felfüggesztésére egy újabb megszakítási kérelem által. A
kiválasztó logika a kiszolgálás közben érkezett megszakítások közül a legmagasabb prioritású engedélyezett megszakítás-kérést engedélyezi. Az 1-es forrás szerinti kérés feldolgozása hosszabb ideig is eltarthat, viszont az 0-ás forrás megszakítás-kérése esetleg nem tűrhet ekkora halasztást. 1 INT 0 2 normál felh.-i szint t 1 2 0 0 2 • Többszintű: keresi a pillanatnyi CPU-szintnél magasabb prioritás-szintű engedélyezett megszakításkéréseket. Kiválasztja a legalacsonyabb prioritás-szintűt PSW-csere esetén ez oly módon zajlik le, hogy a megszakított szint PSW-je Old PSW-ként tárolódik, a másik rekesz tartalma pedig New PSW-ként betöltődik a programállapot-regiszterbe. Az elfogadott megszakítás-kérés nyugtázódik Ha nem talál az utolsó szintnél magasabb prioritású engedélyezett kérést, akkor megengedi a legutolsó New PSW-ben megjelölt utasítás végrehajtását. -60 0 1 2 3 1 1 2 1 2 0 t 2 •
Kompromisszum: az előző kettő ötvözése, azaz szinteket rendelnek a megszakítások egy-egy csoportjához Szinten belül egyszintű, szintek között többszintű 0/a 0 1 2 3 1/a 1/a 2/a 2/b 1/a 0/a t 2/a 2/a 2/b 2/b Pentium processzorok megszakítási rendszere Megszakítás (interrupt) maszkolható nem maszkolható eltérülés (exception) programozott processzor által felismert CPU - interrupt exception 1. megszakítás: a program működésével aszinkron (processzoron kívüli esemény) a. maszkolható: a processzor INTR lábára érkező megszakítás 1) INTR kérés 2) INTACK (a visszaigazolás, hogy elfogadva) 3) Vektor beolvasása 4) A vektortáblázat a megszakítást kezelő rutinok kiválasztása b. nem maszkolható: a processzor NMI lábára érkező megszakítás 2. eltérülés: a program működésével szinkron (processzoron belüli események) a. programozott eltérülés: INT N (tetszőleges sorszámú megszakítás) b. processzor által
felismert eltérülés (∆) A vektortáblázat • Valós módban egy bejegyzése 4 byte, a tábla neve megszakítási vektortábla • Védett módban egy bejegyzése 8 byte, a tábla neve megszakítási deszkriptortábla (IDTR – Interrupt Descriptor Table) • A táblából a kiszolgáló rutin kezdőcíme olvasható ki ∆ • • • • -7FAULTS (hibák): minden esetben az utasítás végrehajtása előtt kiderülnek (0-val való osztás) TRAPS (csapdák): utasítás végrehajtás után, azok következményeként fordulnak elő pl. INT 1 vagy túlcsordulás ABORTS (végzetes hibák): a CPU nem tudja meghatározni a hibát Pl. - CPU-n belüli hiba - rendszertábla hibás kitöltése MVE azonosító Megszakítások valós módban • NMI + eltérülések 0.31 0: osztáshiba 1: debug (nyomkövetés: minden utasítás után megáll) 2: NMI 3: töréspont 4: INTO (a túlcsordulás kezelése) 5: BOUND (index-határ) 6: nem megengedett műveleti kód 13: általános védelmi
hiba 14: laphiba 17: illeszkedés ellenőrzés • 32.255 maszkolható megszakítások IRQ0: timer IRQ1: billentyűzet IRQ4: infraport IRQ5: SD memóriakártya IRQ6: floppy IRQ9: videó kártya és hálózati kártya IRQ11: rádió kártya IRQ12: egér Az IF flag jelzi, hogy engedélyezve vannak-e a maszkolható INT-ek (1 esetén igen). Ezen flag beállítására való Assembly utasítások: CLI (Clear INT) és STI (Set INT) Daisy chain: A megszakítási kérelem helyének meghatározása a visszaigazoló IACK vezeték segítségével, sorosan történik. A visszaigazoló jel a kiszolgálást kérő egységtől már nem halad tovább, hasonlóan a sínkérelmek kiszolgálásához. Ez pedig elindítja a kiszolgáló rutint A megszakítás visszaigazolása sorosan halad végig az eszközökön, evvel meghatározva azok prioritását is egyúttal. Címzési módok Címzési mód: ahogy a címet meghatározzuk, pontosabban egy címszámítási algoritmus. MK OP1 OP2 Címzési módok
címszámítás 1. Címszámítás, címmegadás: • abszolút címzés: MK Cím címmódosítás címértelmezés -8- MK után teljes cím van, o Előny: a teljes operatív tár megcímezhető. o Hátrány: a cím hosszú (4-6 byte), így lassú • relatív címzés MK Y=B+D D D: displacement (eltolás) B: base (bázis) A bázis lehet: o dedikált regiszter (Rbi) /i-edik/ o programszámláló (PC) o TOS (Top of Stack – A stack teteje) o Operatív tárbeli mutató (OPT) (Yp) A címszámítás lehet: Rbi PC Y=B TOS +B Yp - Bázisregiszteres A báziscímhez adódik hozzá az előjeles eltolás. Így ’B’ egy környezete érhető el - Bázislapos Mindegyik lap ugyanakkora. Így elérhető pl az x-edik lap ötödik byte-ja Az eltolásnak nincs negatív értelmezése. P D 16 2 PC F8 A8 MK D8 PC F 8 256 lap D8 hossza 256 1 D 0 P: a lapcím lehet: - PC (futólapos címzés) - 0 (0 lapos címzés) - D: lapon belüli eltolás • Közvetlen adatmegadás
(IMMEDIATE) pl. MOV AX , 13 közvetlen adatmegadás MK Közv. ADAT MK OP1 OP2 -9• Rejtett, implicit címzés A műveleti kód utal az adatra: pl. egy flag értéke beállítható (STI/CLI) pl. POP AX (SP=SP+1; (SP) AX ) MK OP1 OP2 2. Címmódosítás • Indexelés: egy lineáris adatstruktúra egyetlen eleméhez férünk hozzá S Rxi Ye = S + ( Rxi ) + { Rxj }, Ahol Rxj egy indexregiszter (egyszeres indexelés) Ye • Autoinc/Autodec o az egyes elemek egymás utáni elérése: Az index értékét az utasítás automatikusan csökkenti vagy növeli. o mindkettő történhet címzés előtt vagy címzés után - 10 - A valós cím meghatározásának tervezési tere (címdeklaráció) címzés Címszámítás abszolút címmódosítás relatív Rbi PC TOS Yp indexelés auto inc/dec egyszeres dupla többszörös indexelés sorrendje pre- képlettel: (Yabs) (Rbi) (PC) (TOS) (Yp) Y= +D + Rbk + Rxj postindexelés pre post irány + - +1 -1 3.
Címértelmezés • Direkt/indirekt Direkt esetén az Y egyértelműen meghatározza az adat helyét, indirekt esetén egy címre mutat, amely meghatározza az adat helyét. (többszörösen indirekt is lehet) Direkt MK Cím Adat indirekt MK Cím Cím Cím Adat • Valós/virtuális Címtér valós (fizikai-ram) virtuális (logikai) VT virtuális tárkezelés programozó ezt látja - 11 - A 16/32 bites Intel processzorok regiszterei (programozhatóak) Funkciók: • A-D: általános célú regiszterek • • (E)AX: szorzó, osztó utasítások (E)BX: indirekt periféria-címzés (E)CX: számláló jellegű reg. (léptetés, ciklus) (E)DX: szorzó, osztó utasítások, I/O műveletek (E)BP: bázis pointer, paraméterátadás (a stack-ből ki lehet venni az eljárás paramétereit) (E)SI: index regiszter, stringkezelő utasítások (E)DI: index regiszter, stringkezelő utasítások (E)SP: stack pointer CS: code segment DS: data segment ES: data segment (FS): data
segment (GS): data segment SS: stack segment • • • • • • • • • • • • Újdonságok az i80386-ban: • 32 bites regiszterek (EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP) • két új adatszegmens (FS, GS) • VM: virtuális 8086 mód • RF (Resume): időszakosan letiltja a nyomkövetési hibákat (debug fault), hogy egy ilyen után folytatni lehessen egy utasítást anélkül, hogy újabb hibák keletkeznének • NT: megszakított és meghívott taskok láncolása • IOPL: I/O Privilege Level (védelmi szint): az I/O címtartományhoz való hozzáférés ellenőrzésére Memória-hivatkozási típus Bázis Bázis2 Offset Utasítás lehívás CS IP Stack művelet SS SP Változó DS CS, ES, SS Effektív cím String forrás DS CS, ES, SS SI String cél ES DI BP mint bázisregiszter SS CS, DS, ES Effektív cím Minden egyes szegmens báziscíme tárolva van. Egy szegmensen belüli adat megcímzéséhez a 32 bites offsetet hozzá kell adni a szegmens báziscíméhez
SS – egy eljárás meghívása előtt egy memóriaterületet kell kijelölni a verem számára. Ez a regiszter a verem szegmens azonosítására való (kívülről is hozzáférhető) DS-GS – biztosítják a különböző adatstruktúrákhoz való megfelelő hozzáférést (az alkalmazói program futása közben is feltölthetők) CS - a végrehajtandó utasítások szegmens-szelektorát alkalmazza AH – felső bájtok, LH – alsó bájtok (a regiszter-táblázatban) - 12 Flag regiszterek (a FLAGS részei): • Státusz flagek: CFCarry: átvitel bit PFParity: hibajavításra használt, páros számú 1-esre javít AFAuxiliary Carry: BCD-nél az értéke 1, ha átvitel van. ZFZ flag: ha a keletkezett eredmény 0, akkor a bit értéke 1 (pl. ha egy csökkenő ciklus elérte a nullát) SFSignum: ha a legfelső bit 1-es, akkor negatív (előjel) OFOverflow: túlcsordulás • Rendszer flagek: AC: illeszkedés ellenőrzés: ha értéke 1, akkor illeszkedési hibás az operandus
kivétel keletkezik. Pl páratlan címen 2 bájtos utasításra hivatkozás vagy néggyel nem osztható címen DWORD-re hivatkozás (4 bájt) VM: ha 1, virtuális 8086 mód TFTrap: ha 1, akkor minden utasítást követően egy hibakereső kivételt generál IFInterrupt: megszakítás (INTR), maszkolása (CLI, STI) • Vezérlő flag: DFDirection: 8086, stringkezelő utasítások (SI, DI) 2 regiszter memória. kezeli a növelést, csökkenést az autoinc/dec esetén. Utasítások általános formája Az utasítás hossza legfeljebb 6 byte lehet: Az 1.byte: • OP. KOD (6): Az első 6 bit a műveleti kód • D (1): 0 esetén regiszterből, 1 esetén regiszterbe irányul a művelet. műveleteknek így két gépi kódja is lehet. • W (1): 0 esetén byte-os (8 bit), 1 esetén word-ös (16 bit) a művelet Egyes A 2. byte határozza meg a maximálisan két operandus elérési módját: MOD (2): címzési mód. REG (3): Regiszter kiválasztás. • R/M (3): Regiszter vagy memória.
• • A 3. byte az első operandus, cím vagy adat alacsony byte-ja: • LOW DISP vagy DATA (8) A 4. byte az első operandus, cím vagy adat magas byte-ja: • HIGH DISP vagy DATA (8) Az 5. byte a második operandus, az adat alacsony byte-ja: • LOW DATA (8) A 6. byte a második operandus, az adat magas byte-ja: • HIGH DATA (8) Általánosan igaz, hogy ha egy kétoperandusú utasítás egyike a memóriában van, akkora másik csak regiszterben lehet. - 13 - Ha minden igaz, akkor ezt nem kéri vissza, de sose lehet tudni REG 000 001 010 011 100 101 110 111 W=1 AX CX DX BX SP BP SI DI W=0 AL CL DL BL AH CH DH BH MOD 00 01 10 11 11 R/M 000 BX +SI D=8 BX + SI + D D = 16 BX + SI + D W=0 AL W=1 AX 001 BX + DI BX + DI + D BX + DI + D CL CX 010 BP + SI BP + SI + D BP + SI + D DL DX 011 BP + DI BP + DI + D BP + DI + D BL BX 100 SI SI + D SI + D AH SP 101 DI DI + D DI + D CH BP 110 Direkt Address BX BP + D BP + D DH SI BX + D BX + D
BH DI 111 A memóriák típusai Szervezés: Egy bitnyi információ tárolása (DRAM vagy SRAM) CS: Chip Select WE: Write Enable (felülvonás0-ra aktívak) Két bit egy bemenetet aktivál (4 eset). Minden esetben mátrix elrendezésű. 16*1 bit szervezésű vagy 44 szó szervezésű 1024*1024=220=1 Mbit-es cella Az első tíz bit az első dekóderbe, a másik 10 bit a második dekóderbe kerül, így nem kell 20 bemenetet készíteni. RAS: Row Address Strobe CAS: Column Address Strobe. - 14 - DRAM W – kiválasztó vezeték. 1) olvasás: kisütjük a kondit, így a töltések eltávoznak. Vissza kell írni. (R+W) 2) írás: a kondi feltöltése A kapacitás nagyon kicsi, ezért a töltése könnyen elszivárog: frissíteni kell. (~ 2ms-ként egy olvasás művelet szükséges) Pl.: 16 K * 1tár 128 128-as mátrix A frissítés történhet: a. Régebben: a DMA vezérlő egy látszólagos olvasás segítségével frissített; az eredményt nem használta fel b. ma: egységen
belüli megoldás 2ms Frissítési módszerek C • BURST Refresh (a teljes memória frissül) 2ms • DISTRIBUTED Refresh (folyamatosan frissül) 2ms . 2ms/128 idő cellánként MK Dek Op1 (frissítés, ha a processzor nem használja az adott területet) • Transparent Refresh • Részei: fetch (előkészít) és execute (végrehajt) Fetch: Pl. itt Fetch o A műveleti kód kiolvasása a memóriából (használja a memóriát) o Dekódolás (nem használjra – regiszterművelet) o A két operandus kiolvasása (általában használja a memóriát) 1 CLK RAS 2 4 5 t1 t2 t * SOR OSZLOP t t R/W D 6 t CAS A 3 Op2 t Érvényes adat t - 15 CLK: buszfrekvencia A: címvezeték D: adatvezeték 4, 5: lehet akár 1 ciklus is olvasás: t1: sor -és oszlopcím kiolvasása t2: adat megjelenítéséhez és a jel visszavétele t1 + t2 ~ 60ns (6+6+6+6+) ns egy ciklus (5+5+5+5+) ns, ha gyorsabb a busz A hozzáférés gyorsítása 1, Cím-folytonos olvasás:
egyszerre több bitet olvasunk a mátrixból, így a RAS jelet elég csak egyszer kiadni. (6+4+4+4 ns) – Fast Page Mode DRAM Nibble Mode FPM DRAM: 4 rekeszes RAM 1. az első olvasásnál rákerülnek a címek, a RAS és a vezérlőjel 2. a címek növelése az IC-n belül történik, nincs külső címzés Mindez a CAS-hez szinkronizálva; (6+4+4+4 ciklus) Ez akkor előny, ha a CPU 4 bájtos egységekben hívja le az adatot OPT-ból, és folyamatosan tudja fogadni az adatokat. Extended Data Out DRAM = EDORAM +1 kimenet bevezetése (tároló) a nCAS visszabillenésének tárolására. A kimeneti adat érzékelését ehhez kötik: előbb indulhat a kiolvasás (egy ciklus megspórolása) 6+3+3+3ciklus – Output Enable nOE // nX = X negáltja Burst Extended Data Out DRAM = BEDO RAM Nincs szükség az oszlop vezérlőjelre, a címeket az IC-n belül generálja. Saját címszámlálóval és belső pipeline-nal rendelkezik. A bemenetén már megjelenik az új adat, amikor a kimenetére
kerül az előző adat (6+2+2+2ciklus) Synchronous DRAM = SDRAM Az olvasás a CPU vezérlőjeléhez van szinkronizálva, nem pedig a CAS-RAS-hoz. 5+1+1+1 ciklus 1 SDRAM lapra 4db Bank (4*8 bit) 8 8 8 8 Memory Interleaving ( 32 bites 4 GB 4*1) 14 84 0 4 8 12 1 5 9 13 0 nCS - 16 - 2 6 10 14 1 nCS 3 7 11 15 2 nCS 3 nCS A1 A2 8 8 8 8 LOW ORDER HIGH ORDER 14 84 0 0 1 0 0 1 1 0 1 1 0 0 1 0 0 1 1 1 0 0 1 0 1 0 0 1 1 LOW ( - ) HIGH ( | ) 0 MEMORY INTERLEAVING: 8db SDRAM Dual Inline Memory Module (DIMM) 0 1 2 7 32 byte-os DIMM kimeneti Buffer és 64 bit a CPU felé DRAM olvasása: R+W TC: ciklusidő Hozzáférési idő RECOVERY TIME: a következő olvasásig eltelő idő CPU - 17 Adat ki Tárhozzáférési idő: a kereséstől a megjelenítésig. Ciklusidő: kéréstől az új kérésig Az Interleave Addressing technikával az adat megjelenése után egy másik modulból rögtön indulhat a kiolvasás, nincs recovery time. Külön szegmensben
helyezkedik el az adat, a kód és a stack. Rambus DRAM • teljesen új architektúra, több egymástól független memóriamodult tartalmaz • rendkívül nagy belső cache-tárja van (1M-hoz 2K cache), • NINCS nRAS, nCAS helyette 1 lépésben kapja meg a címet • Blokkos az adatátvitel; blokk: 8db 256 bájt terjedelmű, adatszélesség: 8bit • Gyors blokkmozgatás, speciális illesztő-áramkör szükséges (rambus) • Nagyon drága, mert az eltérő technológia miatt más gyártósort igényel DDR SDRAM SDRAM esetén a művelet a felfutó élre van szinkronizálva, míg a DDR SDRAM esetén a lefutóra is. • A belső memória lapokra van bontva: az egyik rekeszben adatforgalom, a másikba beolvasás • Nagyon gyors belső órajelgenerátor és pipeline • Kompatibilis a jelenlegi gyártási technikával Összefoglalva: DRAM [ns] [Mb/s] 60 100 FPM EDO Aszinkron burst 40 25 200 266 BEDO SDRAM RDRAM DDR szinkron 15 532 15/10/7,5 4/3,3 1600 7,5/6/5 DDR: PC
2100: 2100 Mb/s PC 2700: 2700 Mb/s PC 3200: 3200 Mb/s / / / 266MHz 333MHz 400MHz / / / 7,5ns 6ns 5ns Cache memóriák A CPU és az OPT közötti sebességkülönbség: 8MHz 125ns, 500MHz 20ns, 1GHz 1ns • Wait State: Azon állapot, amikor a CPU az olvasási kérelem kiadása után várakozni kénytelen a memóriára • Megoldás: Gyors memória a CPU lapkájára (nem kell a lassú buszon át komm.) o A CPU így drága lesz o A lapkák nem lehetnek tetszőleges méretűek Nagyméretű, de lassú tár (OPT) Kisméretű, de gyors tár (Cache) Cache: speciális gyorsító tár PC-ben (L = Level): • L1 – CPU-ban • L2 – dedikált buszon kapcsolódik a CPU-val • L3 – alaplap • Grafikus kártya - 18 • HDD Méretek: L1: 16K ~ 64K; n*10K L2: 512K ~ 1M; n*100K L3: n*1M Lokalitási elv: egy rövid időintervallum alatt a memóriahivatkozások csak a memória egy kis részét érintik. 1. térbeli: azokra a memóriahelyekre, amelyeknek a címe
számszerűen hasonló a nemrégiben elért memóriahely címéhez, valószínűleg hamar szükség lesz. Ezért a cache-be több adatot hozunk be, mint éppen szükséges. 2. időbeli: sokszor ugyanazon adatokra van szükség (ciklusok belsejének ismétlődése miatt) Átlagos hozzáférési idő: c + m – h * m = c + ( 1 - h) m ahol: Cache: ~1ns (c) OPT: ~5ns (m) találati arány: ~ 90% (h) (ilyen arányban lesz a szükséges adat a cache-ben) A Főtár és a cache tár aktualizálása: • átíró (Write Through): amikor a cache-be ír, akkor az OPT-be is: lassú (486 CPU) • visszaíró (Write Back): A cache tár mérete kisebb, mint az OPT, így az adatátvitel blokkokban történik. Ha a cache telítve van, kimentjük a tartalmát az OPT-be, majd a bejövő adattal felülírjuk (Pentium-tól) CPU Ha a C betelik algoritmus kiválaszt egy blokkot, amelyet visszaír az OPT-ba és helyére érkezik az újabb adat OPT C new old • késleltetett írás (Burst Write): akkor
írja vissza az adatot az OPT-ba, amikor az nincs használatban (Pl. a CPU belső műveletet végez, nem használja az OPT-t) A memória-hierarchia lehetséges alternatívái az adat cache szempontjából Gyorsul, a mérete pedig csökken L1 M CPU rendszermemória 1. variáció (486) adat L2 M L2 L3 2. variáció (Pentium) utasítás M 3. variáció (Itanium) Külön L1: az adatnak és az utasításnak Tendencia: Az L2 már a CPU-n belül, az L3 pedig dedikált buszon. A gyorsítótárak általában egyre bővülők: az L1 teljes tartalma benne az L2-ben, és így tovább. Minden gyorsítótár a következő modellt használja. A főmemória fel van osztva rögzített méretű blokkokra (cache line = 4-64 byte) Amikor memóriahivatkozás történik, a gyorsítótár vezérlő áramköre megvizsgálja, hogy a kért adat megvan-e gyorsítótárban. Ha nincs ott az adat, akkor valamelyik vonalbejegyzést kivesszük a cache-ből, és helyette a szükséges adatot betöltjük a
memóriából vagy a magasabb szintű gyorsítótárból. - 19 Cél: minél több szükséges adat legyen a cache-ben, hogy ne kelljen a lassú memóriához fordulni. Az adat cache tervezési terének alapkomponensei Az adat cache tervezési tere Adat cache (makro)architektúra A cache funkcionális leírása (Black Box) • írási és olvasási eljárások • hibavédelem Adat cache mikroarchitektúra Belső struktúra Műveletek (LAYOUT) (operational) • Cache-szervezés • A CPU és a cache összekapcsolása • „Tagging Scheme” o On-Chip • Cache Line (egy sor a o Off-Chip cache-ben egy blokk) • A Cache line mérete • PORT a CPU és a (32-64-128 byte) cache hány porton keresztül csatlakozik (1-3) • Adatszélesség – hány bájtos • BANK single, • A CPU és a cache multibank; 2, 4, 8 (A szinkronizálása portok számának (párhuzamosság) megfelelő bankot tud • A cache tár órajele egyszerre elérni a CPU) Szervezés • Közvetlen leképzésű
(DIRECT MAPPED) A gyorsítótárban minden sor pontosan egy gyorsítótárvonalat tartalmazhat a főmemóriából. Egy 32 bájtos vonalmérettel a gyorsítótár 64KB-ot tartalmazhat. Minden sor három részből áll: - 20 V (Valid): egy bit jelzi, hogy van-e a sorban érvényes adat. Amikor a rendszer indul, minden sort érvénytelennek jelölünk meg. Tag: egy egyedi, 16 bites értékből áll, amely a megfelelő memóriavonalat azonosítja, ahonnan az adat jött. D (Data): a memóriában lévő adat másolatát tartalmazza. Ez a mező egy 32 bájtos gyorsítótárvonalat tartalmaz. Egy adott memóriaszó pontosan egy helyen lehet tárolva a gyorsítótáron belül. Az adatok tárolásához és kinyeréséhez négy alkotóelemre tagoljuk a címet, amit a CPU állít elő: TAG: a cache-ben tárolt Tag bitek megfelelője LINE: megmutatja, hogy melyik sor tartalmazza a szükséges adatokat, ha azok jelen vannak. WORD: azt mondja meg, hogy egy vonalon belül melyik szóra történt
hivatkozás. BYTE: ha csak egy bájtra érkezik kérés, ez mondja meg, hogy a szón belül melyik bájtra van szükség. Egy olyan cache-nél, amely csak 32 bites szavakat szolgáltat, ez a mező mindig 0. Amikor a CPU előállít egy memóriacímet, a hardver kiveszi a címből a 11 LINE bitet, és indexelésre használja a cache-ben. Ha a vizsgált sor érvényes, akkor a memóriacím TAG mezője összehasonlítódik a cache sorának Tag mezejével. Ha megegyeznek, és a sor tartalmazza a keresett szót, az a cache-hit (találat) Az éppen szükséges szót kivesszük, a sor többi részével nem foglalkozunk. Ha a sor érvénytelen, vagy a címkék nem egyeznek meg, az a cache-miss (hiány). Ekkor a 32 bájtos vonal betöltődik a memóriából a cache-be. Ha a felülírandó sor a betöltés óta módosult, akkor vissza kell írni a memóriába, mielőtt eldobnánk. Mivel legfeljebb 64KB (211 x 8 x 4) egymás mellett lévő adatot tárolhatunk a cache-ben, ezért két olyan vonal,
amelyek között a különbség 64KB egész számú többszöröse, nem lehet egy időben a cache-ben tárolva (ugyanaz a címzésre használt LINE értékük). Például, ha egymás után ilyen helyen lévő adatokra van szükség, akkor a cache bejegyzése kénytelen újratöltődni, az ott lévő sort pedig ki kell írni a memóriába. Ebben a legrosszabb esetben az egész rendszer lassabb, mintha nem lenne gyorsítótár. (ritkán fordul elő) Ez az összeütközés nem fordul elő, ha külön van választva az utasítás –és adatcache, mivel a különböző kéréseket más gyorsítótárak fogják kiszolgálni. Előnye, hogy a szó kiolvasása a cache-ből, és továbbítása a CPU-hoz ugyanabban az időben történhet, amikor eldől, hogy a vizsgált a megfelelő szó. Így a CPU valójában párhuzamosan, vagy akár még előbb megkap egy szót a cache-ből, mielőtt megtudná, hogy az a kívánt szó. Pl Alpha 21064(A), UltraSparc 1-2 Összeütközés: 0. 0.31 1. 32.63 2.
64.85 2047 65504-65535 65536-65567 65568-65599 Ezekből csak egy 32 byteos része kerülhet a cache-be, mivel a line részük többféle is lehet • Csoportos asszociatív cache (n-way set associative) CL 16 byte Az összeütközés feloldására ennek a cache-nek minden címhez n lehetséges bejegyzése van. Ekkor a hivatkozott memóriacímből kiszámítható a bejegyzés helye, de egy n elemű halmazban kell megkeresni a megfelelő sort. Amikor egy új bejegyzést hozunk be a cache-be, el kell döntenünk, hogy melyiket dobjuk el. Elég jó algoritmus a legtöbb esetre az LRU (Least Recently used). Ez egy sorrendet tart fenn a helyek minden olyan halmazáról, amely elérhető egy adott memóriahelyről. Ha a vonalak valamelyikéhez hozzáférünk, ez frissíti a listát. Így mindig a lista végén lévő, tehát legutolsóként használt lesz az, amit eldobunk A 4 utas feletti cache szokatlan, mivel gyakran rosszabb a teljesítményük. - 21 2 utas: Pentium, Pentium Pro,
AMD Athlon; 4 utas: UltraSparc 3, Pentium II-III-IV; 8 utas: Power PC 602 TAG 168 0 110 133 A négyes csoport, amit az index megcímez LRU: HB Sz 4 utas cache 26 *16 4 = 4K Sz: számláló HB: használati bit Ha használjuk HB=1 I Sz := 0 N Sz += 1 HB=0;
megszakítás? Elfogadja? t ∆t n más művelet Megszakításkérő jel generálódott megszakítás Állapot mentése Elindítja azt a rutint, amely kiszolgálja a megszakítást Visszaállítás Visszatérés I/O művelet vége Az, hogy elfogad-e egy megszakítást, azt jelenti, hogy az éppen zajló folyamat megszakítható-e egy új kedvéért. Ha igen, menti az aktuális állapotot, majd elvégzi a feladatot, tehát megszünteti a kiváltó okot. -2A megszakítások forrásai 1. Géphibák: • az egyes eszközök valamilyen hibajavító kód segítségével ismerik fel a hibákat o A CPU regiszterei o Operatív tár o Adatátvitel • Energiaellátás hibái • Klimatizáció 2. I/O források: a perifériák megszakítás-kérő jelzései (CPU dobozon belül) 3. Külső források másik számítógép 4. Programozói források Utasítások végrehajtásakor keletkező INT-ek: • Hiba (arch. specifikusak) o Memóriavédelem megsértése o Tárkapacitás
túlcímzés (tényleges) o Címzési előírások megsértése o Aritmetikai és logikai műveletek miatti megszakítás (kivételek:tömbindex-túlcímzés, 0-val való osztás, overflow) • Szándékos o Rendszerhívások (pl. az Intel CPU-k overflow flag-je jelzi, ha túlcsordulás lépett fel Az INTO utasítással egy megszakítás kérhető: korrekció.) Megszakítások csoportosítása • Szinkron/aszinkron • Utasítások végrehajtása között (az előző utasítás eredményeképpen) vagy közben (külső) történő megszakítások Ellenélda: REP mov SB DS:SI ES DI SI++ DI++ Flag: Overflow 1 0 1 0 0 1 1 0 CX 0 1 0 • Felhasználó által explicit módon kért ill. nem kért megszakítások o Kért (az OPrendszer szolgáltatásai): Pl. INTO vagy INT3 (a programban való töréspont elhelyezésére használható, a hibakeresés érdekében (debug)) o Nem Kért: magától a gép • Felhasználó által maszkolható (letiltható) vagy nem maszkolható
megszakítások Megszakítás-kiszolgálás 1. egy egység aktiválja az INTR bemenetet 2. a CPU elfogadja ezt az INT kérést, ha megszakítható állapotban van megfelelő a prioritás nagysága a beérkezett megszakítás nincs maszkolva A 3 felt. teljesülése esetén INT elfogadva UT1 UT2 . a megszakítás vizsgálása (két ut. között nem fogadóképes) Megszakítási flagregiszter: a még nem teljesített INT kérések vannak benne 3. CPU elmenti a verembe az aktuális állapot információkat (PC, flag) -34. a megszakított program adatterének mentése (regiszterkészlet) 5. a megszakítást igénylő azonosítása (ha egy INT-hez több egység is tartozik) 6. megszakítás kiszolgálása 7. az adattér visszaállítása 8. A CPU a kiszolgálás végeztével visszaküld egy nyugtát az egységnek, az pedig deaktiválja a jelet A megszakítás kiszolgálása után a megszakított program folytatódik, vagy nem (reset). Mindegyik INT-hez tarozik egy bit:
a CPU ezeket vizsgálja, amikor fogadóképes. A megszakítást kérő azonosítása A legegyszerűbb lehetőség a megszakítások egyenkénti kiszolgálása, azok beérkezési sorrendjében. Hátránya, hogy a megszakítások kiszolgálása közben érkező megszakítást nem tudja kiszolgálni, így a halaszthatatlan kérelmek elveszhetnek. 1. Lekérdezéses (polling): Valamilyen sorrendben lekérdezzük az egységeket • Hardveres úton: daisy chain • Szoftveres úton: az operációs rendszer 2. Vektoros: A megszakítást kérő eszköz a kiszolgáló rutin kezdőcímét határozza meg a megszakítási vezérlő és a processzor számára. Több megszakítási vonal esetén minden eszköz saját megszakítást kérő vezetékkel rendelkezik, így a kérelem helye egyértelműen megállapítható. Megszakítások maszkolása • NMI: Non Maskable Interrupt (nem maszkolható megszakítás) • INTR: maszkolható megszakítás Egyes eszközök esetén a megszakítás lehetősége
engedélyezhető vagy tiltható. Ez a maszkolás, ami egy regiszter bitjeinek a beállításával történik. Így az NMI kérelmek kiszolgálása nem tiltható le, azok mindig érvényre jutnak. Parancs az elemzésre Aktuális prioritás Kiválasztó logika Elfogadta a prioritást Elfogadott prioritás maszk regiszter A megszakítási kérelmek kiszolgálási sorrendjének megállapítása történhet megszakítási vezérlővel (centralizált) és decentralizált módon (daisy chain). A memóriavédelem megsértése: Ha az operatív memóriában egy időben több, egymástól független feladat programja tárolódik, szükség van azok védelmének megszervezésére, elsősorban véletlen felülírás ellen. Ha egy program futása során "idegen" címre hivatkozik, az alkalmazott hardveres memória-védelem működésbe lép Pl. ha több program egyszerre akar elérni egy memóriaterületet (Win9x) A címzési mód megsértése: A bájt-szervezésű gépeknél az
utasítások hossza általában 2, 4 vagy 6 bájt lehet. Ez szokásosan együtt jár azzal a címzési előírással, hogy utasítás csak páros című bájttal kezdődhet. Ha például egy ugró utasítás páratlan címre ugrana, ez programhibát jelent és ezért végrehajtás helyett megszakítás történik. Hasonló címzési előírás lehet, például hogy dupla szó csak 8-cal osztható című bájttal kezdődhet. -4Prioritások kezelése Több megszakítás érkezett. Melyik a fontosabb? • Prioritás nélküli: pl. érkezési sorrend alapján időérzékeny megszakítások nem megfelelő kezelése (pl. a soros portra érkező adatot azonnal fogadni kell, különben adatvesztés) • Prioritásos Prioritási csoport: 1. védelmi rendszer megsértése és hardver hibák 2. kritikus időzítések (pl adatátvitel) 3. teljesítményt kell figyelembe venni magasabb prioritású felhasználó nagy terheltségű program Prioritás eldöntésének algoritmusa
(programozhatók általában) • Fix prioritás: az egységekhez van hozzárendelve, nem módosítható • Körbeforgó prioritás – több eszköz rendelkezik azonos prioritással először a C hajtódik végre, utána az ilyen típusúnak lesz a legkisebb a prioritása (de csak az azonos prioritásúak között) A B C Azonos prioritás • Speciális maszk (letilthatók a bizonyos egységektől érkező kérések) A prioritásos megszakítás-kezeléshez hasonló módszerek • Hardver lekérdezéses (daisy chain) databus * INTACK CPU 1 1 U1 0 0 1 1 U1 1 0 1 0 U1 0 1 0 0 U1 0 1.U3 0 2.U2 INTR • • Szoftver lekérdezéses: A programban beállított vizsgálati sorrend határozza meg a prioritást. Prioritási csoportok szervezése -5- • Párhuzamos kiszolgálású megszakítási rendszer Megszakítási rendszerek szintek szerint • Egyszintű: Nincs lehetőség a kiszolgáló rutin felfüggesztésére egy újabb megszakítási kérelem által. A
kiválasztó logika a kiszolgálás közben érkezett megszakítások közül a legmagasabb prioritású engedélyezett megszakítás-kérést engedélyezi. Az 1-es forrás szerinti kérés feldolgozása hosszabb ideig is eltarthat, viszont az 0-ás forrás megszakítás-kérése esetleg nem tűrhet ekkora halasztást. 1 INT 0 2 normál felh.-i szint t 1 2 0 0 2 • Többszintű: keresi a pillanatnyi CPU-szintnél magasabb prioritás-szintű engedélyezett megszakításkéréseket. Kiválasztja a legalacsonyabb prioritás-szintűt PSW-csere esetén ez oly módon zajlik le, hogy a megszakított szint PSW-je Old PSW-ként tárolódik, a másik rekesz tartalma pedig New PSW-ként betöltődik a programállapot-regiszterbe. Az elfogadott megszakítás-kérés nyugtázódik Ha nem talál az utolsó szintnél magasabb prioritású engedélyezett kérést, akkor megengedi a legutolsó New PSW-ben megjelölt utasítás végrehajtását. -60 0 1 2 3 1 1 2 1 2 0 t 2 •
Kompromisszum: az előző kettő ötvözése, azaz szinteket rendelnek a megszakítások egy-egy csoportjához Szinten belül egyszintű, szintek között többszintű 0/a 0 1 2 3 1/a 1/a 2/a 2/b 1/a 0/a t 2/a 2/a 2/b 2/b Pentium processzorok megszakítási rendszere Megszakítás (interrupt) maszkolható nem maszkolható eltérülés (exception) programozott processzor által felismert CPU - interrupt exception 1. megszakítás: a program működésével aszinkron (processzoron kívüli esemény) a. maszkolható: a processzor INTR lábára érkező megszakítás 1) INTR kérés 2) INTACK (a visszaigazolás, hogy elfogadva) 3) Vektor beolvasása 4) A vektortáblázat a megszakítást kezelő rutinok kiválasztása b. nem maszkolható: a processzor NMI lábára érkező megszakítás 2. eltérülés: a program működésével szinkron (processzoron belüli események) a. programozott eltérülés: INT N (tetszőleges sorszámú megszakítás) b. processzor által
felismert eltérülés (∆) A vektortáblázat • Valós módban egy bejegyzése 4 byte, a tábla neve megszakítási vektortábla • Védett módban egy bejegyzése 8 byte, a tábla neve megszakítási deszkriptortábla (IDTR – Interrupt Descriptor Table) • A táblából a kiszolgáló rutin kezdőcíme olvasható ki ∆ • • • • -7FAULTS (hibák): minden esetben az utasítás végrehajtása előtt kiderülnek (0-val való osztás) TRAPS (csapdák): utasítás végrehajtás után, azok következményeként fordulnak elő pl. INT 1 vagy túlcsordulás ABORTS (végzetes hibák): a CPU nem tudja meghatározni a hibát Pl. - CPU-n belüli hiba - rendszertábla hibás kitöltése MVE azonosító Megszakítások valós módban • NMI + eltérülések 0.31 0: osztáshiba 1: debug (nyomkövetés: minden utasítás után megáll) 2: NMI 3: töréspont 4: INTO (a túlcsordulás kezelése) 5: BOUND (index-határ) 6: nem megengedett műveleti kód 13: általános védelmi
hiba 14: laphiba 17: illeszkedés ellenőrzés • 32.255 maszkolható megszakítások IRQ0: timer IRQ1: billentyűzet IRQ4: infraport IRQ5: SD memóriakártya IRQ6: floppy IRQ9: videó kártya és hálózati kártya IRQ11: rádió kártya IRQ12: egér Az IF flag jelzi, hogy engedélyezve vannak-e a maszkolható INT-ek (1 esetén igen). Ezen flag beállítására való Assembly utasítások: CLI (Clear INT) és STI (Set INT) Daisy chain: A megszakítási kérelem helyének meghatározása a visszaigazoló IACK vezeték segítségével, sorosan történik. A visszaigazoló jel a kiszolgálást kérő egységtől már nem halad tovább, hasonlóan a sínkérelmek kiszolgálásához. Ez pedig elindítja a kiszolgáló rutint A megszakítás visszaigazolása sorosan halad végig az eszközökön, evvel meghatározva azok prioritását is egyúttal. Címzési módok Címzési mód: ahogy a címet meghatározzuk, pontosabban egy címszámítási algoritmus. MK OP1 OP2 Címzési módok
címszámítás 1. Címszámítás, címmegadás: • abszolút címzés: MK Cím címmódosítás címértelmezés -8- MK után teljes cím van, o Előny: a teljes operatív tár megcímezhető. o Hátrány: a cím hosszú (4-6 byte), így lassú • relatív címzés MK Y=B+D D D: displacement (eltolás) B: base (bázis) A bázis lehet: o dedikált regiszter (Rbi) /i-edik/ o programszámláló (PC) o TOS (Top of Stack – A stack teteje) o Operatív tárbeli mutató (OPT) (Yp) A címszámítás lehet: Rbi PC Y=B TOS +B Yp - Bázisregiszteres A báziscímhez adódik hozzá az előjeles eltolás. Így ’B’ egy környezete érhető el - Bázislapos Mindegyik lap ugyanakkora. Így elérhető pl az x-edik lap ötödik byte-ja Az eltolásnak nincs negatív értelmezése. P D 16 2 PC F8 A8 MK D8 PC F 8 256 lap D8 hossza 256 1 D 0 P: a lapcím lehet: - PC (futólapos címzés) - 0 (0 lapos címzés) - D: lapon belüli eltolás • Közvetlen adatmegadás
(IMMEDIATE) pl. MOV AX , 13 közvetlen adatmegadás MK Közv. ADAT MK OP1 OP2 -9• Rejtett, implicit címzés A műveleti kód utal az adatra: pl. egy flag értéke beállítható (STI/CLI) pl. POP AX (SP=SP+1; (SP) AX ) MK OP1 OP2 2. Címmódosítás • Indexelés: egy lineáris adatstruktúra egyetlen eleméhez férünk hozzá S Rxi Ye = S + ( Rxi ) + { Rxj }, Ahol Rxj egy indexregiszter (egyszeres indexelés) Ye • Autoinc/Autodec o az egyes elemek egymás utáni elérése: Az index értékét az utasítás automatikusan csökkenti vagy növeli. o mindkettő történhet címzés előtt vagy címzés után - 10 - A valós cím meghatározásának tervezési tere (címdeklaráció) címzés Címszámítás abszolút címmódosítás relatív Rbi PC TOS Yp indexelés auto inc/dec egyszeres dupla többszörös indexelés sorrendje pre- képlettel: (Yabs) (Rbi) (PC) (TOS) (Yp) Y= +D + Rbk + Rxj postindexelés pre post irány + - +1 -1 3.
Címértelmezés • Direkt/indirekt Direkt esetén az Y egyértelműen meghatározza az adat helyét, indirekt esetén egy címre mutat, amely meghatározza az adat helyét. (többszörösen indirekt is lehet) Direkt MK Cím Adat indirekt MK Cím Cím Cím Adat • Valós/virtuális Címtér valós (fizikai-ram) virtuális (logikai) VT virtuális tárkezelés programozó ezt látja - 11 - A 16/32 bites Intel processzorok regiszterei (programozhatóak) Funkciók: • A-D: általános célú regiszterek • • (E)AX: szorzó, osztó utasítások (E)BX: indirekt periféria-címzés (E)CX: számláló jellegű reg. (léptetés, ciklus) (E)DX: szorzó, osztó utasítások, I/O műveletek (E)BP: bázis pointer, paraméterátadás (a stack-ből ki lehet venni az eljárás paramétereit) (E)SI: index regiszter, stringkezelő utasítások (E)DI: index regiszter, stringkezelő utasítások (E)SP: stack pointer CS: code segment DS: data segment ES: data segment (FS): data
segment (GS): data segment SS: stack segment • • • • • • • • • • • • Újdonságok az i80386-ban: • 32 bites regiszterek (EAX, EBX, ECX, EDX, EBP, ESI, EDI, ESP) • két új adatszegmens (FS, GS) • VM: virtuális 8086 mód • RF (Resume): időszakosan letiltja a nyomkövetési hibákat (debug fault), hogy egy ilyen után folytatni lehessen egy utasítást anélkül, hogy újabb hibák keletkeznének • NT: megszakított és meghívott taskok láncolása • IOPL: I/O Privilege Level (védelmi szint): az I/O címtartományhoz való hozzáférés ellenőrzésére Memória-hivatkozási típus Bázis Bázis2 Offset Utasítás lehívás CS IP Stack művelet SS SP Változó DS CS, ES, SS Effektív cím String forrás DS CS, ES, SS SI String cél ES DI BP mint bázisregiszter SS CS, DS, ES Effektív cím Minden egyes szegmens báziscíme tárolva van. Egy szegmensen belüli adat megcímzéséhez a 32 bites offsetet hozzá kell adni a szegmens báziscíméhez
SS – egy eljárás meghívása előtt egy memóriaterületet kell kijelölni a verem számára. Ez a regiszter a verem szegmens azonosítására való (kívülről is hozzáférhető) DS-GS – biztosítják a különböző adatstruktúrákhoz való megfelelő hozzáférést (az alkalmazói program futása közben is feltölthetők) CS - a végrehajtandó utasítások szegmens-szelektorát alkalmazza AH – felső bájtok, LH – alsó bájtok (a regiszter-táblázatban) - 12 Flag regiszterek (a FLAGS részei): • Státusz flagek: CFCarry: átvitel bit PFParity: hibajavításra használt, páros számú 1-esre javít AFAuxiliary Carry: BCD-nél az értéke 1, ha átvitel van. ZFZ flag: ha a keletkezett eredmény 0, akkor a bit értéke 1 (pl. ha egy csökkenő ciklus elérte a nullát) SFSignum: ha a legfelső bit 1-es, akkor negatív (előjel) OFOverflow: túlcsordulás • Rendszer flagek: AC: illeszkedés ellenőrzés: ha értéke 1, akkor illeszkedési hibás az operandus
kivétel keletkezik. Pl páratlan címen 2 bájtos utasításra hivatkozás vagy néggyel nem osztható címen DWORD-re hivatkozás (4 bájt) VM: ha 1, virtuális 8086 mód TFTrap: ha 1, akkor minden utasítást követően egy hibakereső kivételt generál IFInterrupt: megszakítás (INTR), maszkolása (CLI, STI) • Vezérlő flag: DFDirection: 8086, stringkezelő utasítások (SI, DI) 2 regiszter memória. kezeli a növelést, csökkenést az autoinc/dec esetén. Utasítások általános formája Az utasítás hossza legfeljebb 6 byte lehet: Az 1.byte: • OP. KOD (6): Az első 6 bit a műveleti kód • D (1): 0 esetén regiszterből, 1 esetén regiszterbe irányul a művelet. műveleteknek így két gépi kódja is lehet. • W (1): 0 esetén byte-os (8 bit), 1 esetén word-ös (16 bit) a művelet Egyes A 2. byte határozza meg a maximálisan két operandus elérési módját: MOD (2): címzési mód. REG (3): Regiszter kiválasztás. • R/M (3): Regiszter vagy memória.
• • A 3. byte az első operandus, cím vagy adat alacsony byte-ja: • LOW DISP vagy DATA (8) A 4. byte az első operandus, cím vagy adat magas byte-ja: • HIGH DISP vagy DATA (8) Az 5. byte a második operandus, az adat alacsony byte-ja: • LOW DATA (8) A 6. byte a második operandus, az adat magas byte-ja: • HIGH DATA (8) Általánosan igaz, hogy ha egy kétoperandusú utasítás egyike a memóriában van, akkora másik csak regiszterben lehet. - 13 - Ha minden igaz, akkor ezt nem kéri vissza, de sose lehet tudni REG 000 001 010 011 100 101 110 111 W=1 AX CX DX BX SP BP SI DI W=0 AL CL DL BL AH CH DH BH MOD 00 01 10 11 11 R/M 000 BX +SI D=8 BX + SI + D D = 16 BX + SI + D W=0 AL W=1 AX 001 BX + DI BX + DI + D BX + DI + D CL CX 010 BP + SI BP + SI + D BP + SI + D DL DX 011 BP + DI BP + DI + D BP + DI + D BL BX 100 SI SI + D SI + D AH SP 101 DI DI + D DI + D CH BP 110 Direkt Address BX BP + D BP + D DH SI BX + D BX + D
BH DI 111 A memóriák típusai Szervezés: Egy bitnyi információ tárolása (DRAM vagy SRAM) CS: Chip Select WE: Write Enable (felülvonás0-ra aktívak) Két bit egy bemenetet aktivál (4 eset). Minden esetben mátrix elrendezésű. 16*1 bit szervezésű vagy 44 szó szervezésű 1024*1024=220=1 Mbit-es cella Az első tíz bit az első dekóderbe, a másik 10 bit a második dekóderbe kerül, így nem kell 20 bemenetet készíteni. RAS: Row Address Strobe CAS: Column Address Strobe. - 14 - DRAM W – kiválasztó vezeték. 1) olvasás: kisütjük a kondit, így a töltések eltávoznak. Vissza kell írni. (R+W) 2) írás: a kondi feltöltése A kapacitás nagyon kicsi, ezért a töltése könnyen elszivárog: frissíteni kell. (~ 2ms-ként egy olvasás művelet szükséges) Pl.: 16 K * 1tár 128 128-as mátrix A frissítés történhet: a. Régebben: a DMA vezérlő egy látszólagos olvasás segítségével frissített; az eredményt nem használta fel b. ma: egységen
belüli megoldás 2ms Frissítési módszerek C • BURST Refresh (a teljes memória frissül) 2ms • DISTRIBUTED Refresh (folyamatosan frissül) 2ms . 2ms/128 idő cellánként MK Dek Op1 (frissítés, ha a processzor nem használja az adott területet) • Transparent Refresh • Részei: fetch (előkészít) és execute (végrehajt) Fetch: Pl. itt Fetch o A műveleti kód kiolvasása a memóriából (használja a memóriát) o Dekódolás (nem használjra – regiszterművelet) o A két operandus kiolvasása (általában használja a memóriát) 1 CLK RAS 2 4 5 t1 t2 t * SOR OSZLOP t t R/W D 6 t CAS A 3 Op2 t Érvényes adat t - 15 CLK: buszfrekvencia A: címvezeték D: adatvezeték 4, 5: lehet akár 1 ciklus is olvasás: t1: sor -és oszlopcím kiolvasása t2: adat megjelenítéséhez és a jel visszavétele t1 + t2 ~ 60ns (6+6+6+6+) ns egy ciklus (5+5+5+5+) ns, ha gyorsabb a busz A hozzáférés gyorsítása 1, Cím-folytonos olvasás:
egyszerre több bitet olvasunk a mátrixból, így a RAS jelet elég csak egyszer kiadni. (6+4+4+4 ns) – Fast Page Mode DRAM Nibble Mode FPM DRAM: 4 rekeszes RAM 1. az első olvasásnál rákerülnek a címek, a RAS és a vezérlőjel 2. a címek növelése az IC-n belül történik, nincs külső címzés Mindez a CAS-hez szinkronizálva; (6+4+4+4 ciklus) Ez akkor előny, ha a CPU 4 bájtos egységekben hívja le az adatot OPT-ból, és folyamatosan tudja fogadni az adatokat. Extended Data Out DRAM = EDORAM +1 kimenet bevezetése (tároló) a nCAS visszabillenésének tárolására. A kimeneti adat érzékelését ehhez kötik: előbb indulhat a kiolvasás (egy ciklus megspórolása) 6+3+3+3ciklus – Output Enable nOE // nX = X negáltja Burst Extended Data Out DRAM = BEDO RAM Nincs szükség az oszlop vezérlőjelre, a címeket az IC-n belül generálja. Saját címszámlálóval és belső pipeline-nal rendelkezik. A bemenetén már megjelenik az új adat, amikor a kimenetére
kerül az előző adat (6+2+2+2ciklus) Synchronous DRAM = SDRAM Az olvasás a CPU vezérlőjeléhez van szinkronizálva, nem pedig a CAS-RAS-hoz. 5+1+1+1 ciklus 1 SDRAM lapra 4db Bank (4*8 bit) 8 8 8 8 Memory Interleaving ( 32 bites 4 GB 4*1) 14 84 0 4 8 12 1 5 9 13 0 nCS - 16 - 2 6 10 14 1 nCS 3 7 11 15 2 nCS 3 nCS A1 A2 8 8 8 8 LOW ORDER HIGH ORDER 14 84 0 0 1 0 0 1 1 0 1 1 0 0 1 0 0 1 1 1 0 0 1 0 1 0 0 1 1 LOW ( - ) HIGH ( | ) 0 MEMORY INTERLEAVING: 8db SDRAM Dual Inline Memory Module (DIMM) 0 1 2 7 32 byte-os DIMM kimeneti Buffer és 64 bit a CPU felé DRAM olvasása: R+W TC: ciklusidő Hozzáférési idő RECOVERY TIME: a következő olvasásig eltelő idő CPU - 17 Adat ki Tárhozzáférési idő: a kereséstől a megjelenítésig. Ciklusidő: kéréstől az új kérésig Az Interleave Addressing technikával az adat megjelenése után egy másik modulból rögtön indulhat a kiolvasás, nincs recovery time. Külön szegmensben
helyezkedik el az adat, a kód és a stack. Rambus DRAM • teljesen új architektúra, több egymástól független memóriamodult tartalmaz • rendkívül nagy belső cache-tárja van (1M-hoz 2K cache), • NINCS nRAS, nCAS helyette 1 lépésben kapja meg a címet • Blokkos az adatátvitel; blokk: 8db 256 bájt terjedelmű, adatszélesség: 8bit • Gyors blokkmozgatás, speciális illesztő-áramkör szükséges (rambus) • Nagyon drága, mert az eltérő technológia miatt más gyártósort igényel DDR SDRAM SDRAM esetén a művelet a felfutó élre van szinkronizálva, míg a DDR SDRAM esetén a lefutóra is. • A belső memória lapokra van bontva: az egyik rekeszben adatforgalom, a másikba beolvasás • Nagyon gyors belső órajelgenerátor és pipeline • Kompatibilis a jelenlegi gyártási technikával Összefoglalva: DRAM [ns] [Mb/s] 60 100 FPM EDO Aszinkron burst 40 25 200 266 BEDO SDRAM RDRAM DDR szinkron 15 532 15/10/7,5 4/3,3 1600 7,5/6/5 DDR: PC
2100: 2100 Mb/s PC 2700: 2700 Mb/s PC 3200: 3200 Mb/s / / / 266MHz 333MHz 400MHz / / / 7,5ns 6ns 5ns Cache memóriák A CPU és az OPT közötti sebességkülönbség: 8MHz 125ns, 500MHz 20ns, 1GHz 1ns • Wait State: Azon állapot, amikor a CPU az olvasási kérelem kiadása után várakozni kénytelen a memóriára • Megoldás: Gyors memória a CPU lapkájára (nem kell a lassú buszon át komm.) o A CPU így drága lesz o A lapkák nem lehetnek tetszőleges méretűek Nagyméretű, de lassú tár (OPT) Kisméretű, de gyors tár (Cache) Cache: speciális gyorsító tár PC-ben (L = Level): • L1 – CPU-ban • L2 – dedikált buszon kapcsolódik a CPU-val • L3 – alaplap • Grafikus kártya - 18 • HDD Méretek: L1: 16K ~ 64K; n*10K L2: 512K ~ 1M; n*100K L3: n*1M Lokalitási elv: egy rövid időintervallum alatt a memóriahivatkozások csak a memória egy kis részét érintik. 1. térbeli: azokra a memóriahelyekre, amelyeknek a címe
számszerűen hasonló a nemrégiben elért memóriahely címéhez, valószínűleg hamar szükség lesz. Ezért a cache-be több adatot hozunk be, mint éppen szükséges. 2. időbeli: sokszor ugyanazon adatokra van szükség (ciklusok belsejének ismétlődése miatt) Átlagos hozzáférési idő: c + m – h * m = c + ( 1 - h) m ahol: Cache: ~1ns (c) OPT: ~5ns (m) találati arány: ~ 90% (h) (ilyen arányban lesz a szükséges adat a cache-ben) A Főtár és a cache tár aktualizálása: • átíró (Write Through): amikor a cache-be ír, akkor az OPT-be is: lassú (486 CPU) • visszaíró (Write Back): A cache tár mérete kisebb, mint az OPT, így az adatátvitel blokkokban történik. Ha a cache telítve van, kimentjük a tartalmát az OPT-be, majd a bejövő adattal felülírjuk (Pentium-tól) CPU Ha a C betelik algoritmus kiválaszt egy blokkot, amelyet visszaír az OPT-ba és helyére érkezik az újabb adat OPT C new old • késleltetett írás (Burst Write): akkor
írja vissza az adatot az OPT-ba, amikor az nincs használatban (Pl. a CPU belső műveletet végez, nem használja az OPT-t) A memória-hierarchia lehetséges alternatívái az adat cache szempontjából Gyorsul, a mérete pedig csökken L1 M CPU rendszermemória 1. variáció (486) adat L2 M L2 L3 2. variáció (Pentium) utasítás M 3. variáció (Itanium) Külön L1: az adatnak és az utasításnak Tendencia: Az L2 már a CPU-n belül, az L3 pedig dedikált buszon. A gyorsítótárak általában egyre bővülők: az L1 teljes tartalma benne az L2-ben, és így tovább. Minden gyorsítótár a következő modellt használja. A főmemória fel van osztva rögzített méretű blokkokra (cache line = 4-64 byte) Amikor memóriahivatkozás történik, a gyorsítótár vezérlő áramköre megvizsgálja, hogy a kért adat megvan-e gyorsítótárban. Ha nincs ott az adat, akkor valamelyik vonalbejegyzést kivesszük a cache-ből, és helyette a szükséges adatot betöltjük a
memóriából vagy a magasabb szintű gyorsítótárból. - 19 Cél: minél több szükséges adat legyen a cache-ben, hogy ne kelljen a lassú memóriához fordulni. Az adat cache tervezési terének alapkomponensei Az adat cache tervezési tere Adat cache (makro)architektúra A cache funkcionális leírása (Black Box) • írási és olvasási eljárások • hibavédelem Adat cache mikroarchitektúra Belső struktúra Műveletek (LAYOUT) (operational) • Cache-szervezés • A CPU és a cache összekapcsolása • „Tagging Scheme” o On-Chip • Cache Line (egy sor a o Off-Chip cache-ben egy blokk) • A Cache line mérete • PORT a CPU és a (32-64-128 byte) cache hány porton keresztül csatlakozik (1-3) • Adatszélesség – hány bájtos • BANK single, • A CPU és a cache multibank; 2, 4, 8 (A szinkronizálása portok számának (párhuzamosság) megfelelő bankot tud • A cache tár órajele egyszerre elérni a CPU) Szervezés • Közvetlen leképzésű
(DIRECT MAPPED) A gyorsítótárban minden sor pontosan egy gyorsítótárvonalat tartalmazhat a főmemóriából. Egy 32 bájtos vonalmérettel a gyorsítótár 64KB-ot tartalmazhat. Minden sor három részből áll: - 20 V (Valid): egy bit jelzi, hogy van-e a sorban érvényes adat. Amikor a rendszer indul, minden sort érvénytelennek jelölünk meg. Tag: egy egyedi, 16 bites értékből áll, amely a megfelelő memóriavonalat azonosítja, ahonnan az adat jött. D (Data): a memóriában lévő adat másolatát tartalmazza. Ez a mező egy 32 bájtos gyorsítótárvonalat tartalmaz. Egy adott memóriaszó pontosan egy helyen lehet tárolva a gyorsítótáron belül. Az adatok tárolásához és kinyeréséhez négy alkotóelemre tagoljuk a címet, amit a CPU állít elő: TAG: a cache-ben tárolt Tag bitek megfelelője LINE: megmutatja, hogy melyik sor tartalmazza a szükséges adatokat, ha azok jelen vannak. WORD: azt mondja meg, hogy egy vonalon belül melyik szóra történt
hivatkozás. BYTE: ha csak egy bájtra érkezik kérés, ez mondja meg, hogy a szón belül melyik bájtra van szükség. Egy olyan cache-nél, amely csak 32 bites szavakat szolgáltat, ez a mező mindig 0. Amikor a CPU előállít egy memóriacímet, a hardver kiveszi a címből a 11 LINE bitet, és indexelésre használja a cache-ben. Ha a vizsgált sor érvényes, akkor a memóriacím TAG mezője összehasonlítódik a cache sorának Tag mezejével. Ha megegyeznek, és a sor tartalmazza a keresett szót, az a cache-hit (találat) Az éppen szükséges szót kivesszük, a sor többi részével nem foglalkozunk. Ha a sor érvénytelen, vagy a címkék nem egyeznek meg, az a cache-miss (hiány). Ekkor a 32 bájtos vonal betöltődik a memóriából a cache-be. Ha a felülírandó sor a betöltés óta módosult, akkor vissza kell írni a memóriába, mielőtt eldobnánk. Mivel legfeljebb 64KB (211 x 8 x 4) egymás mellett lévő adatot tárolhatunk a cache-ben, ezért két olyan vonal,
amelyek között a különbség 64KB egész számú többszöröse, nem lehet egy időben a cache-ben tárolva (ugyanaz a címzésre használt LINE értékük). Például, ha egymás után ilyen helyen lévő adatokra van szükség, akkor a cache bejegyzése kénytelen újratöltődni, az ott lévő sort pedig ki kell írni a memóriába. Ebben a legrosszabb esetben az egész rendszer lassabb, mintha nem lenne gyorsítótár. (ritkán fordul elő) Ez az összeütközés nem fordul elő, ha külön van választva az utasítás –és adatcache, mivel a különböző kéréseket más gyorsítótárak fogják kiszolgálni. Előnye, hogy a szó kiolvasása a cache-ből, és továbbítása a CPU-hoz ugyanabban az időben történhet, amikor eldől, hogy a vizsgált a megfelelő szó. Így a CPU valójában párhuzamosan, vagy akár még előbb megkap egy szót a cache-ből, mielőtt megtudná, hogy az a kívánt szó. Pl Alpha 21064(A), UltraSparc 1-2 Összeütközés: 0. 0.31 1. 32.63 2.
64.85 2047 65504-65535 65536-65567 65568-65599 Ezekből csak egy 32 byteos része kerülhet a cache-be, mivel a line részük többféle is lehet • Csoportos asszociatív cache (n-way set associative) CL 16 byte Az összeütközés feloldására ennek a cache-nek minden címhez n lehetséges bejegyzése van. Ekkor a hivatkozott memóriacímből kiszámítható a bejegyzés helye, de egy n elemű halmazban kell megkeresni a megfelelő sort. Amikor egy új bejegyzést hozunk be a cache-be, el kell döntenünk, hogy melyiket dobjuk el. Elég jó algoritmus a legtöbb esetre az LRU (Least Recently used). Ez egy sorrendet tart fenn a helyek minden olyan halmazáról, amely elérhető egy adott memóriahelyről. Ha a vonalak valamelyikéhez hozzáférünk, ez frissíti a listát. Így mindig a lista végén lévő, tehát legutolsóként használt lesz az, amit eldobunk A 4 utas feletti cache szokatlan, mivel gyakran rosszabb a teljesítményük. - 21 2 utas: Pentium, Pentium Pro,
AMD Athlon; 4 utas: UltraSparc 3, Pentium II-III-IV; 8 utas: Power PC 602 TAG 168 0 110 133 A négyes csoport, amit az index megcímez LRU: HB Sz 4 utas cache 26 *16 4 = 4K Sz: számláló HB: használati bit Ha használjuk HB=1 I Sz := 0 N Sz += 1 HB=0;
 Just like you draw up a plan when you’re going to war, building a house, or even going on vacation, you need to draw up a plan for your business. This tutorial will help you to clearly see where you are and make it possible to understand where you’re going.
Just like you draw up a plan when you’re going to war, building a house, or even going on vacation, you need to draw up a plan for your business. This tutorial will help you to clearly see where you are and make it possible to understand where you’re going.